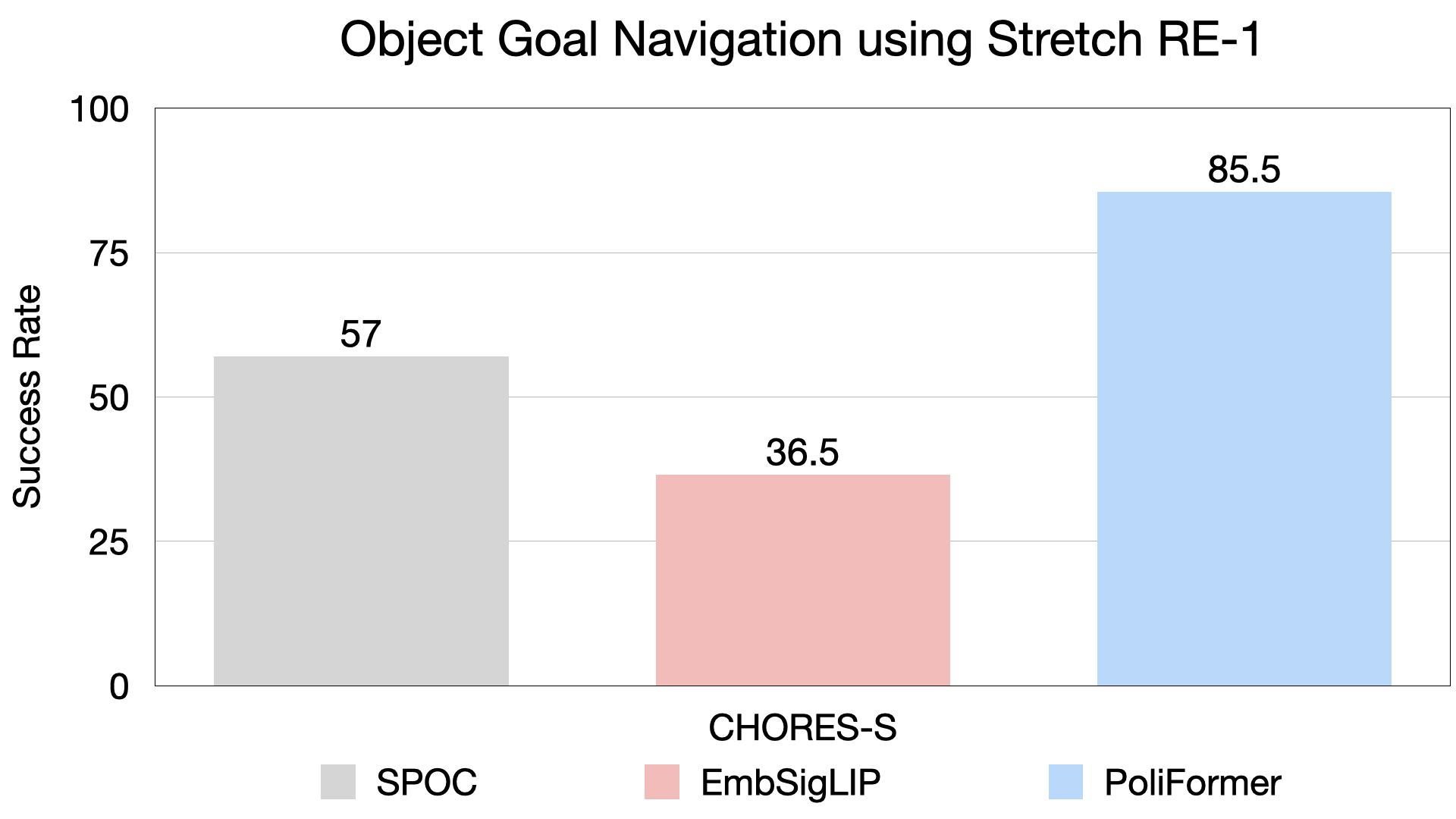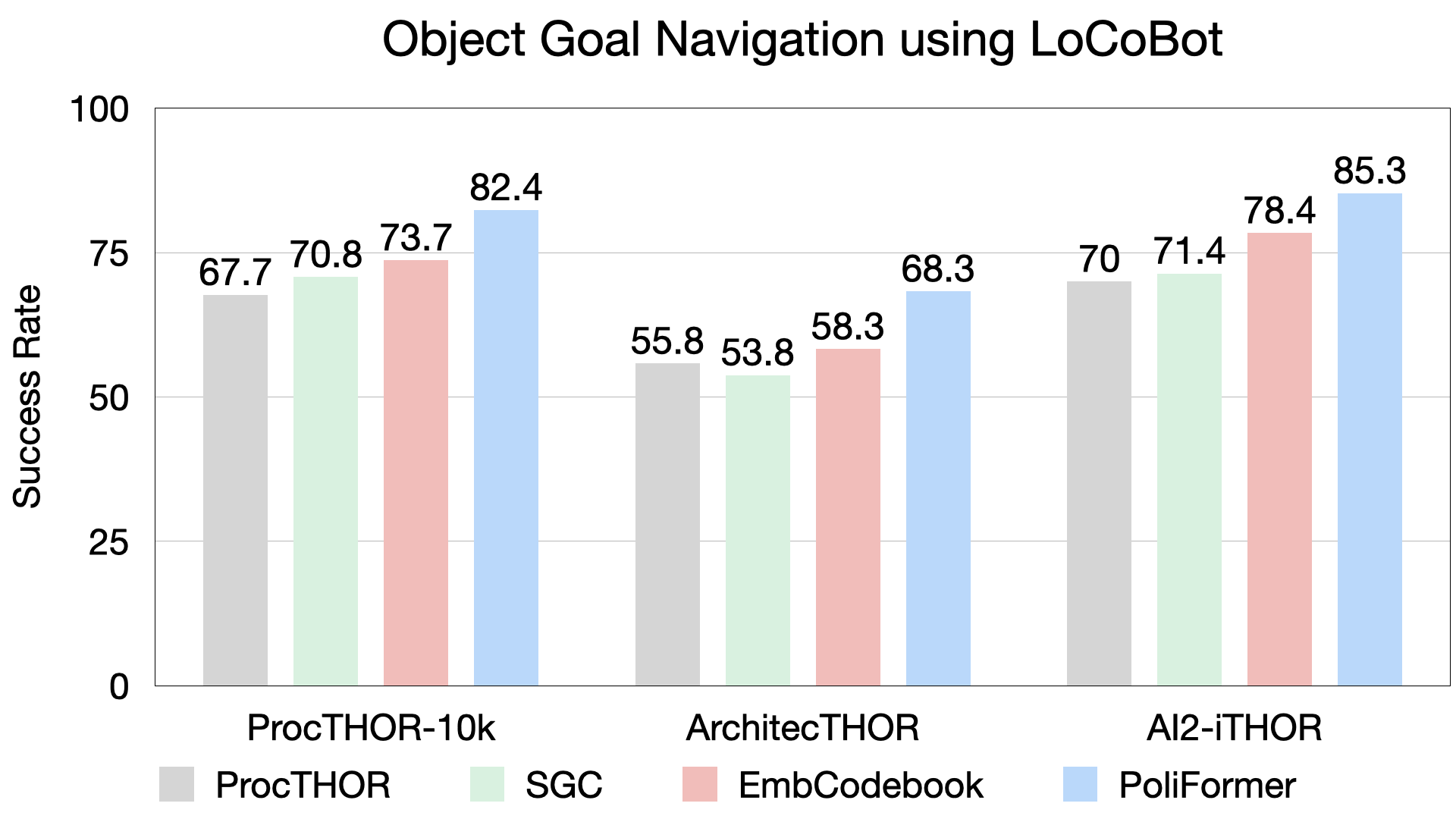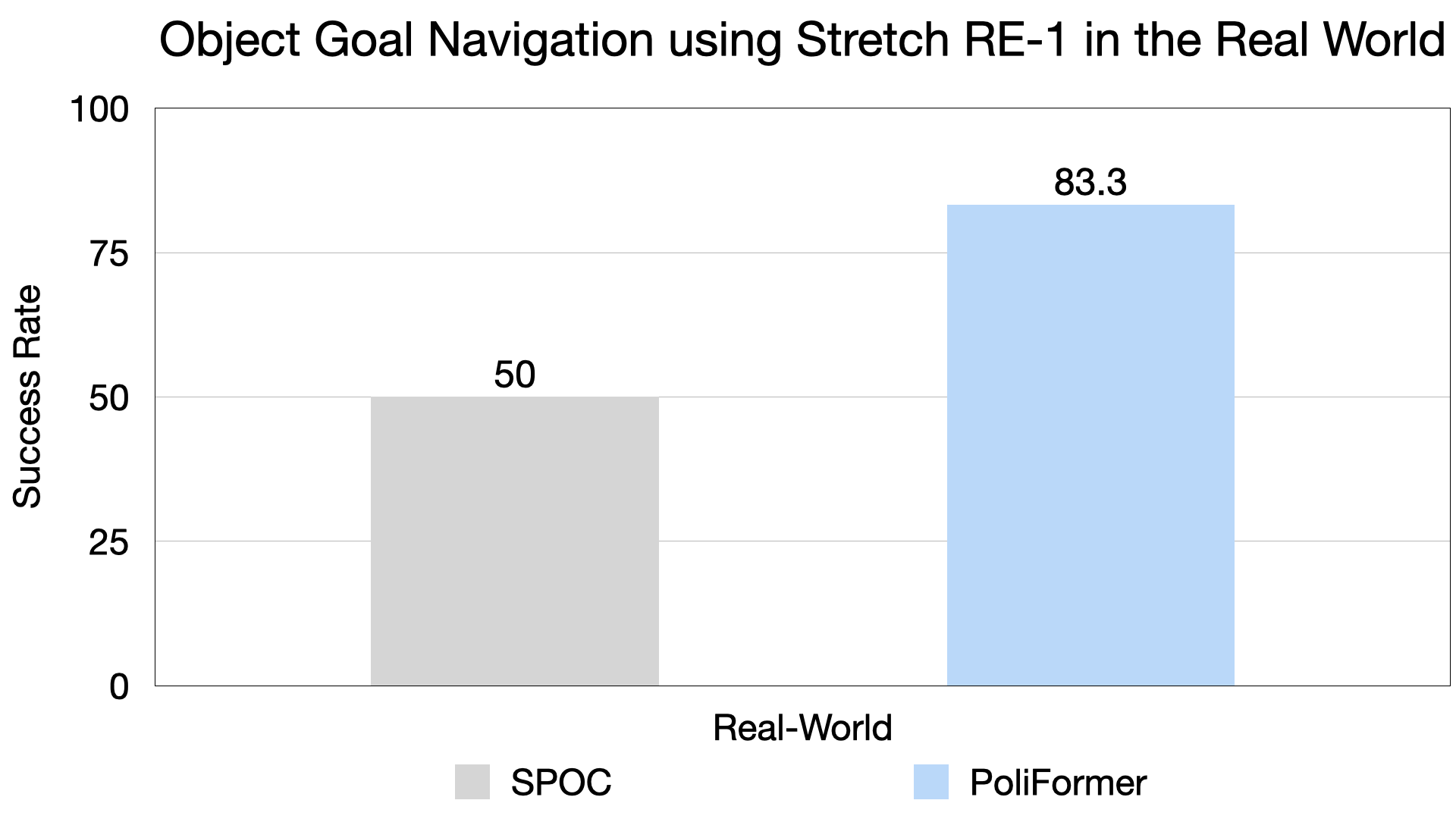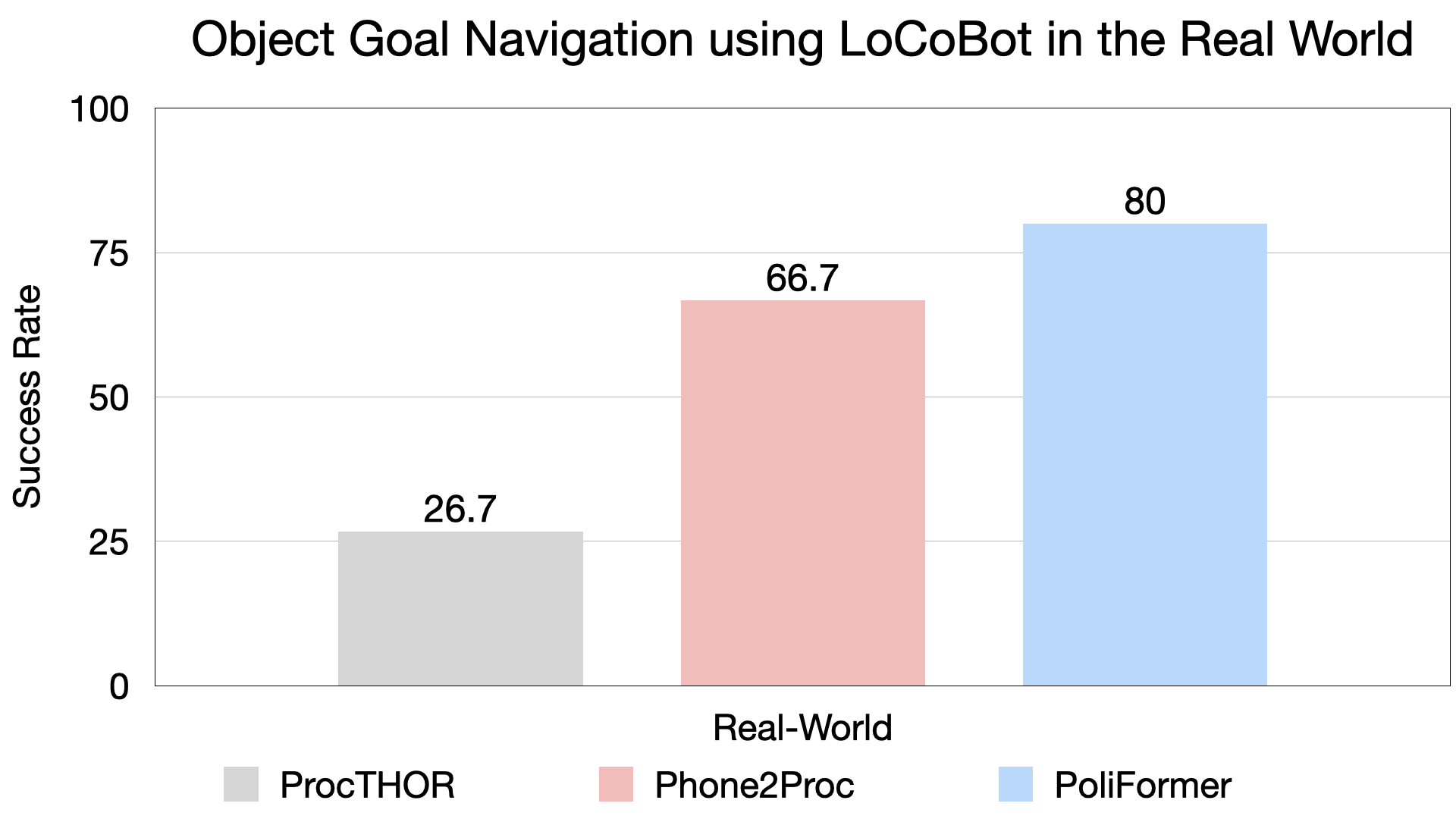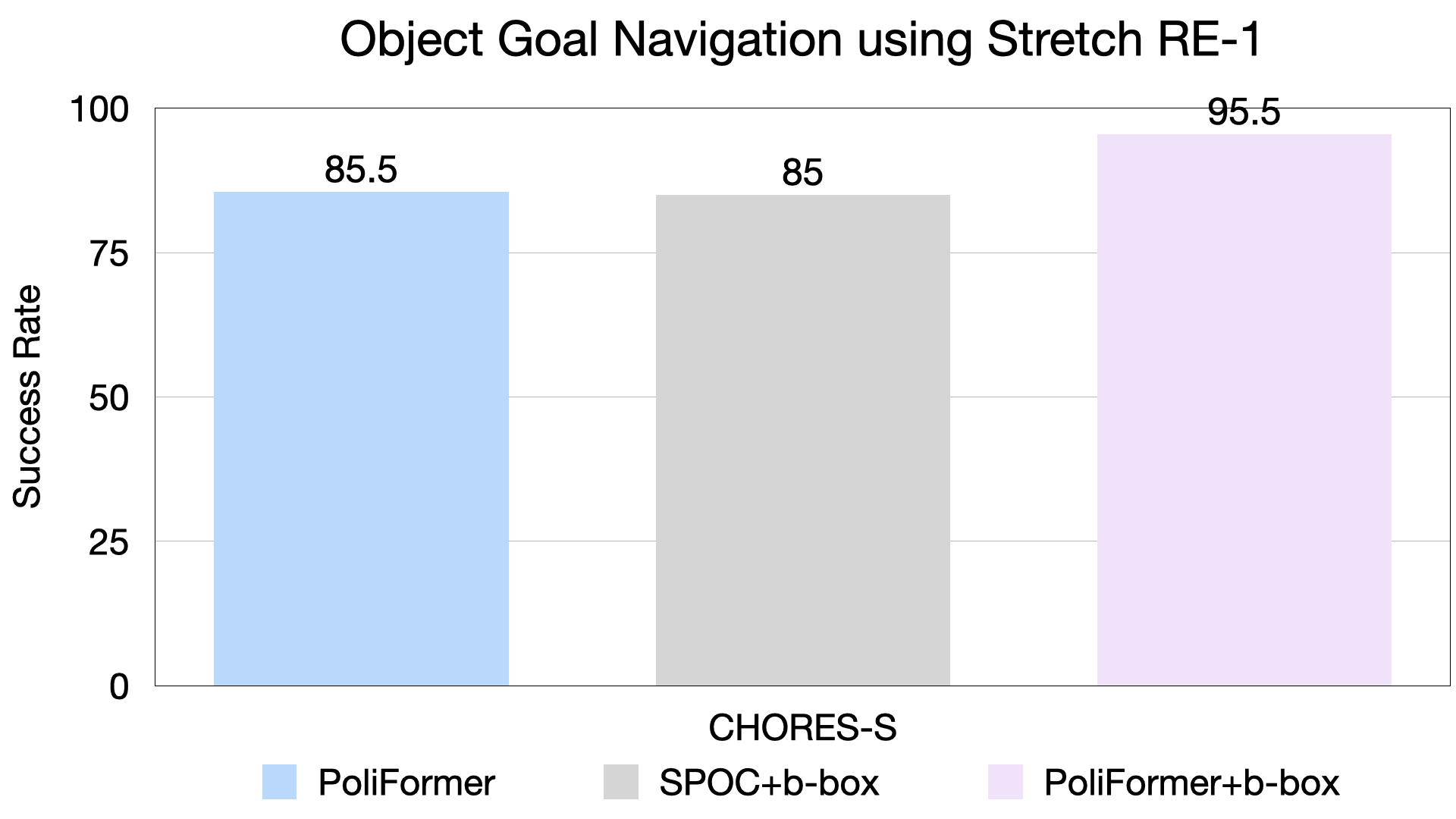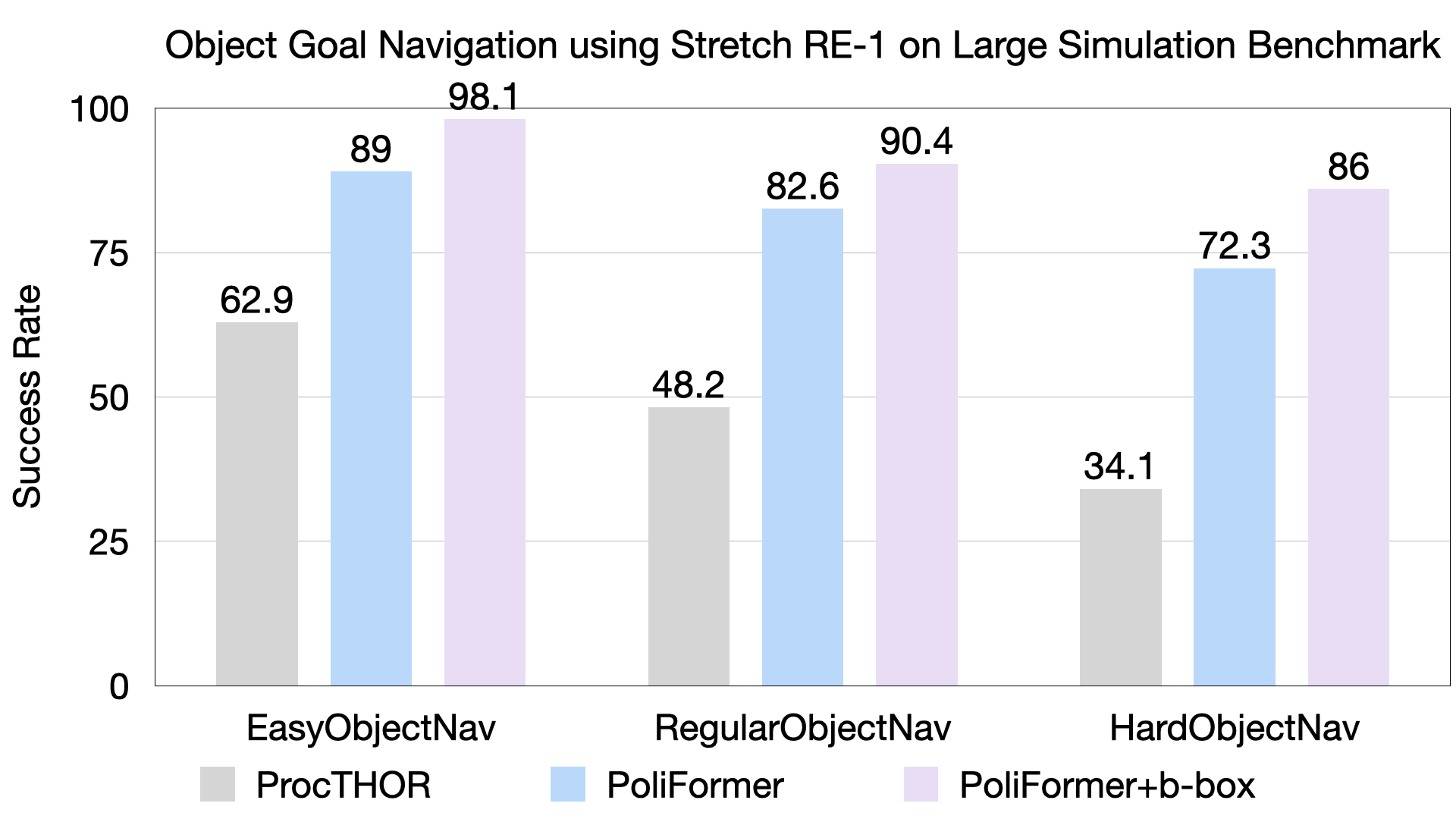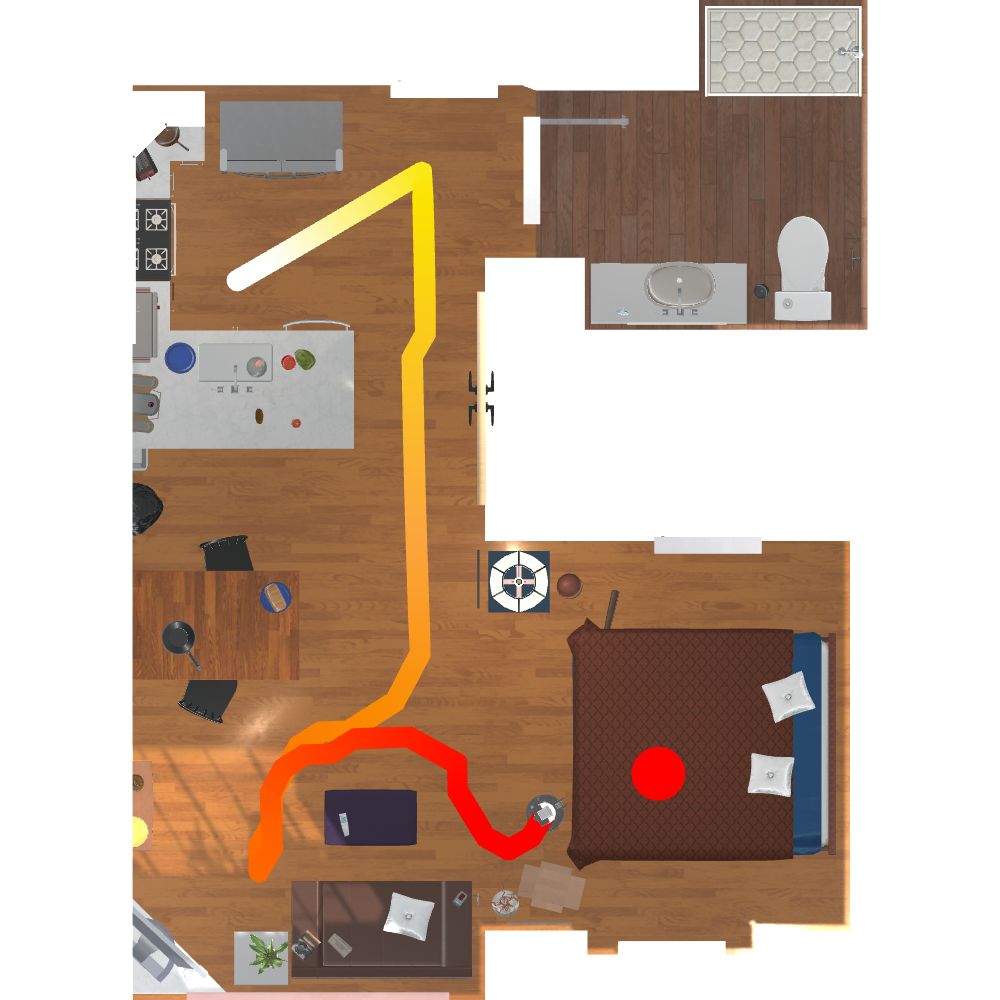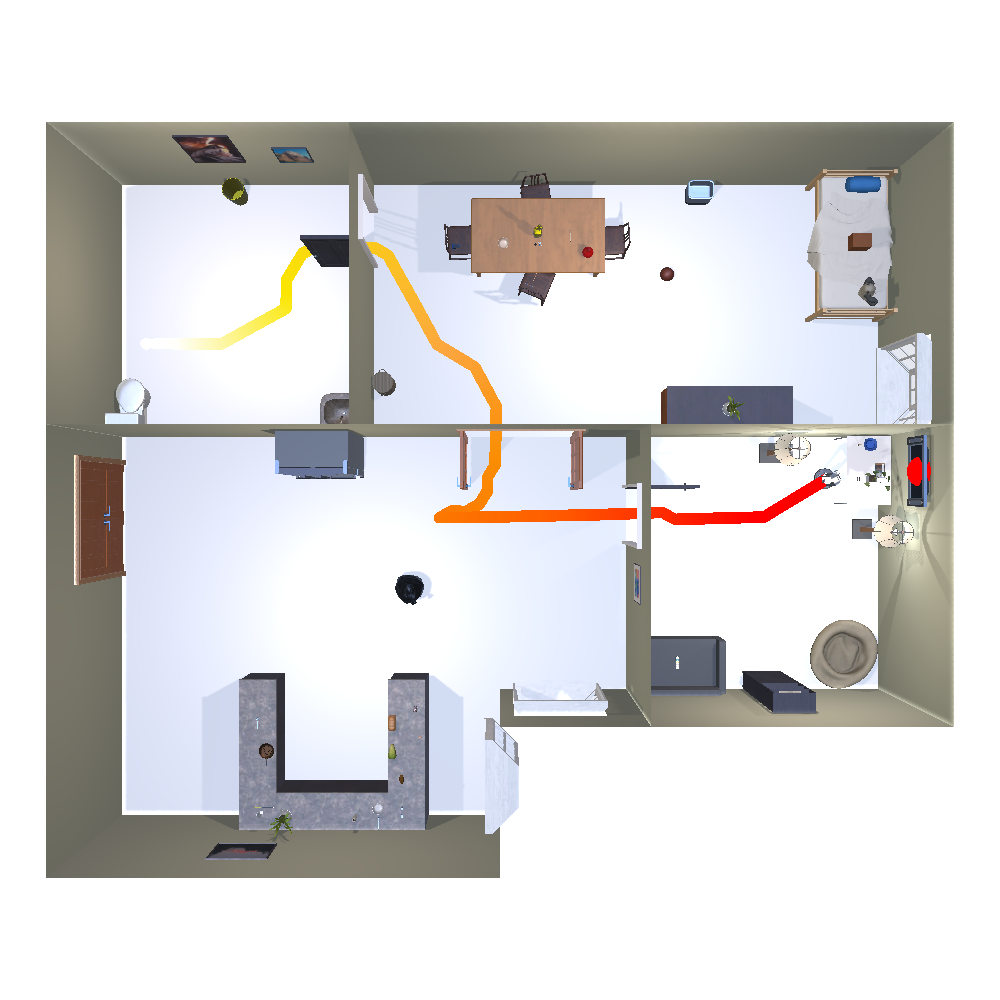
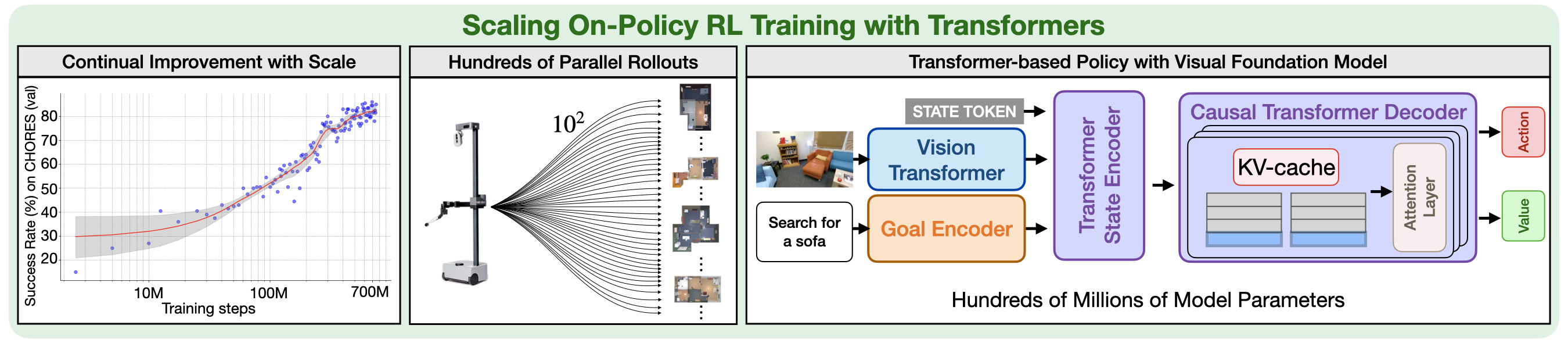
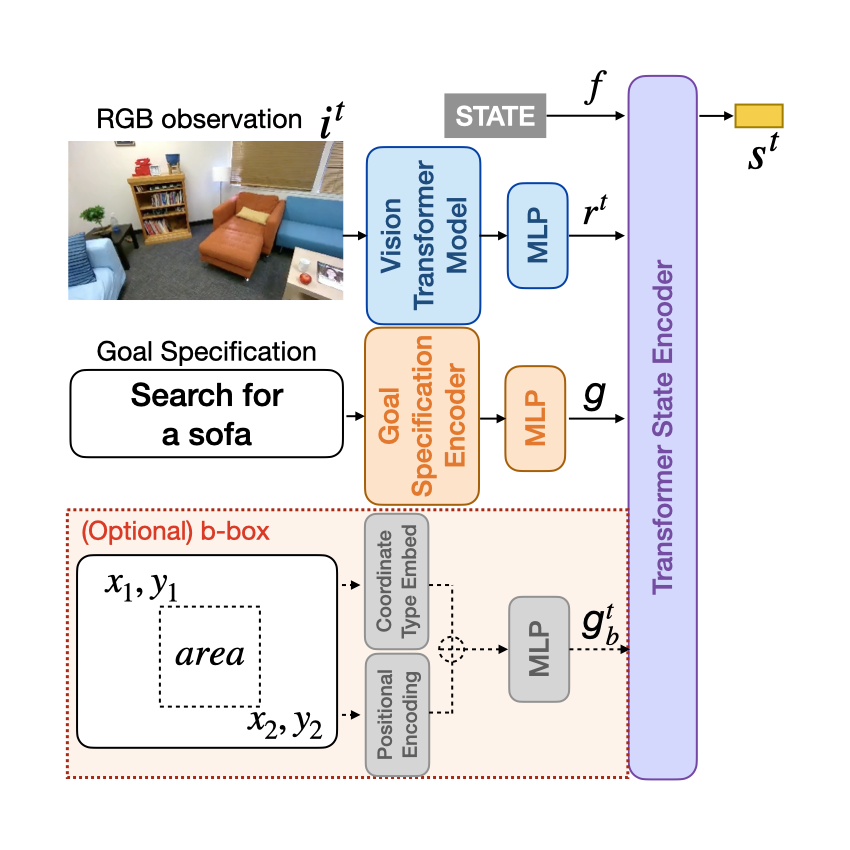
Vision Transformer Model and Transformer State Encoder.
We choose DINOv2 as our visual foundation backbone, because of its remarkable dense prediction and sim-to-real transfer abilities.
The Transformer State Encoder module summarizes the state at each timestep as a vector s. The input to this encoder includes the visual representation v, the goal feature g, and an embedding f of a STATE token.
We concatenate these features together and feed them to a non-causal transformer encoder. This encoder then returns the output corresponding to the STATE token as the state feature vector. Since the transformer state encoder digests both visual and goal features, the produced state feature vector can also be seen as a goal-conditioned visual state representation.
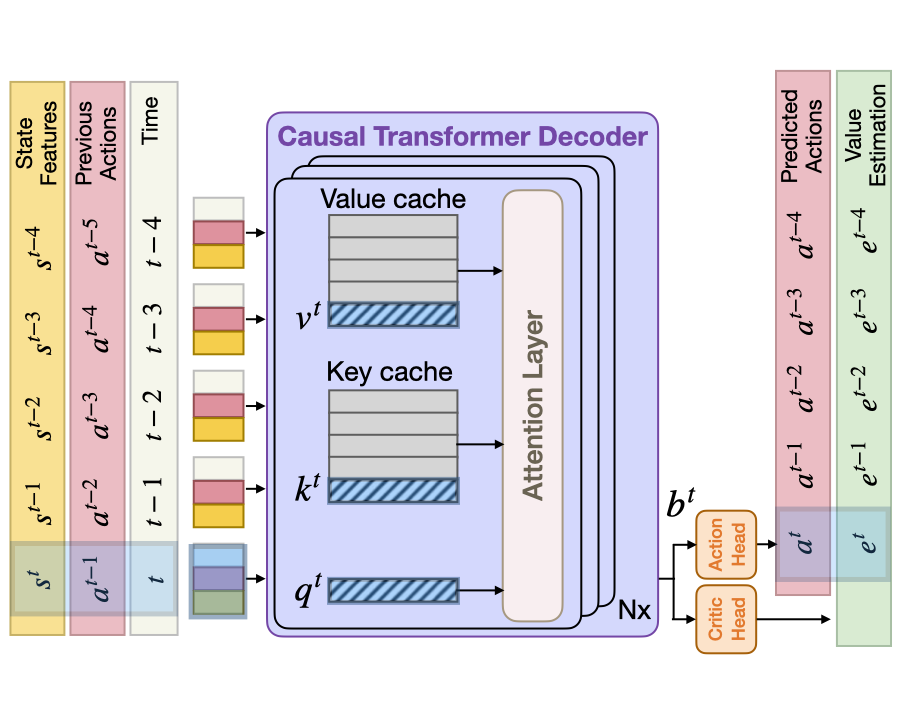
Causal Transformer Deocder with KV-Cache. We use a causal transformer decoder to perform explicit memory modeling over time. This can enable both long-horizon (e.g., exhaustive exploration with back-tracking) and short-horizon (e.g., navigating around an object) planning. Concretely, the causal transformer decoder constructs its state belief b using the sequence of state features s within the same trajectories. During the rollout stage and inference, we leverage the KV-cache technique to keep past feed-forward results in two cache matrices, one for Keys and one for Values. With a KV-cache, our causal transformer decoder only performs feedforward computations with the most current state feature which results in computation time growing only linearly in t rather than quadratically.